Authentic Movie Dialogs
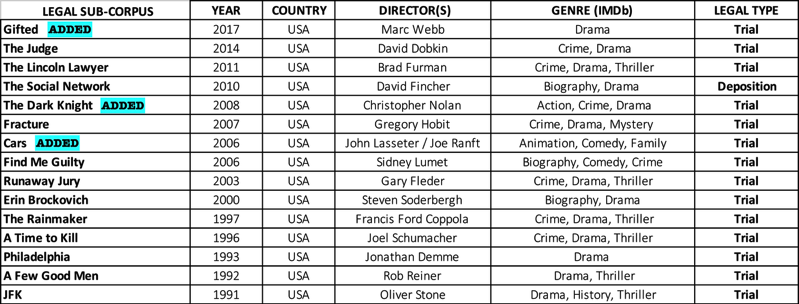
The American Movie Corpus is a structured set of authentic dialogs transcribed by the AMC team which does not include any audiovisual material or script from the web. The current set contains dialogs from movies produced in the United States of America from 1959 to 2019.
Technically, the AMC can be classified as:
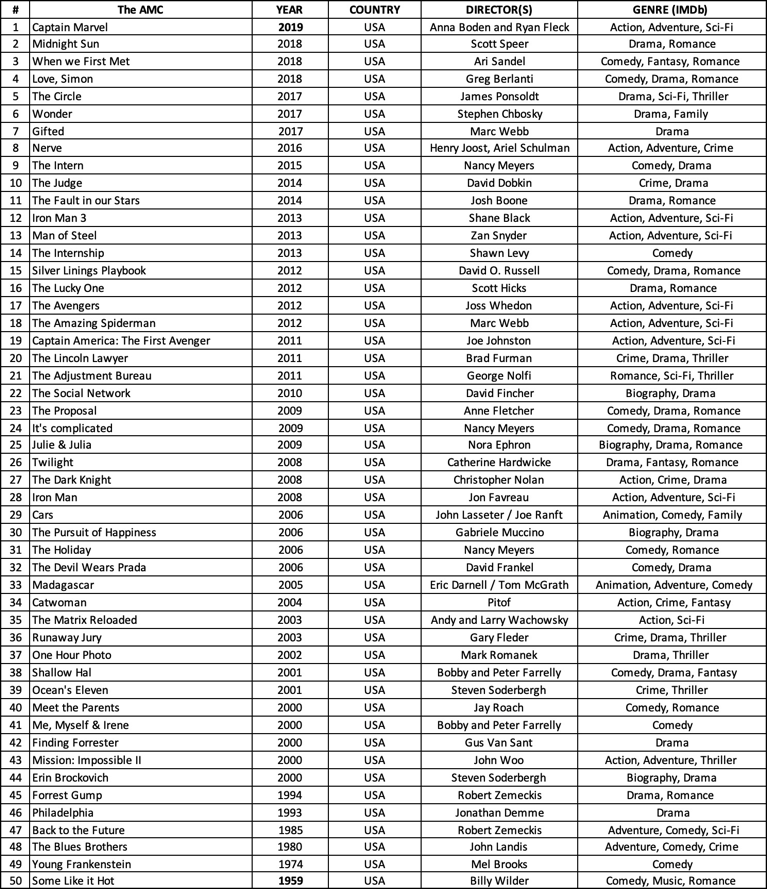
a) A monolingual corpus which, at the present time, contains the original dialogs of the American movies and movie extracts illustrated in the tables below;
b) A sample reference corpus: sample in that it includes a relatively small selection of American movies and, thus, cannot claim to be representative of all movie language, but it aims to provide a representative snapshot. Furthermore, considering its authenticity of dialogs and the developed transcription criteria adopted for the transcriptions, the AMC also aims to serve as a reference corpus for future studies on authentic movie dialogs. In terms of size, the AMC contains dialogs from 50 American movies (i.e. around 570,000 words) and from 15 movie extracts (i.e. around 49,000 words; 28,000 of which are not included in the 50 movies mentioned) which make the size of the AMC around 600,000 words;
c) A monitor/open corpus: in that it is planned to expand and develop over time. This means that other movies or sections from movies will be added with the only restriction being that they are produced in the United States of America and spoken mainly in American English;
d) An adaptable corpus: a term used to emphasize that the AMC can be adapted according to the researcher's needs, purposes and creativity. This implies that it can be accessed in various flexible ways depending on what the corpus is meant to represent and be used for.

Page Background adapted from Jonathan Freyer’s “At The Drive In” (source: https://jonathanfreyer.com/introducing-at-the-drive-in-the-newest-original-work-of-art-by-jonathan-freyer/)